레퍼런스 / 학습 자료
[이희진. 86p ~ 89p 중간까지]
SparkSql 특징
-
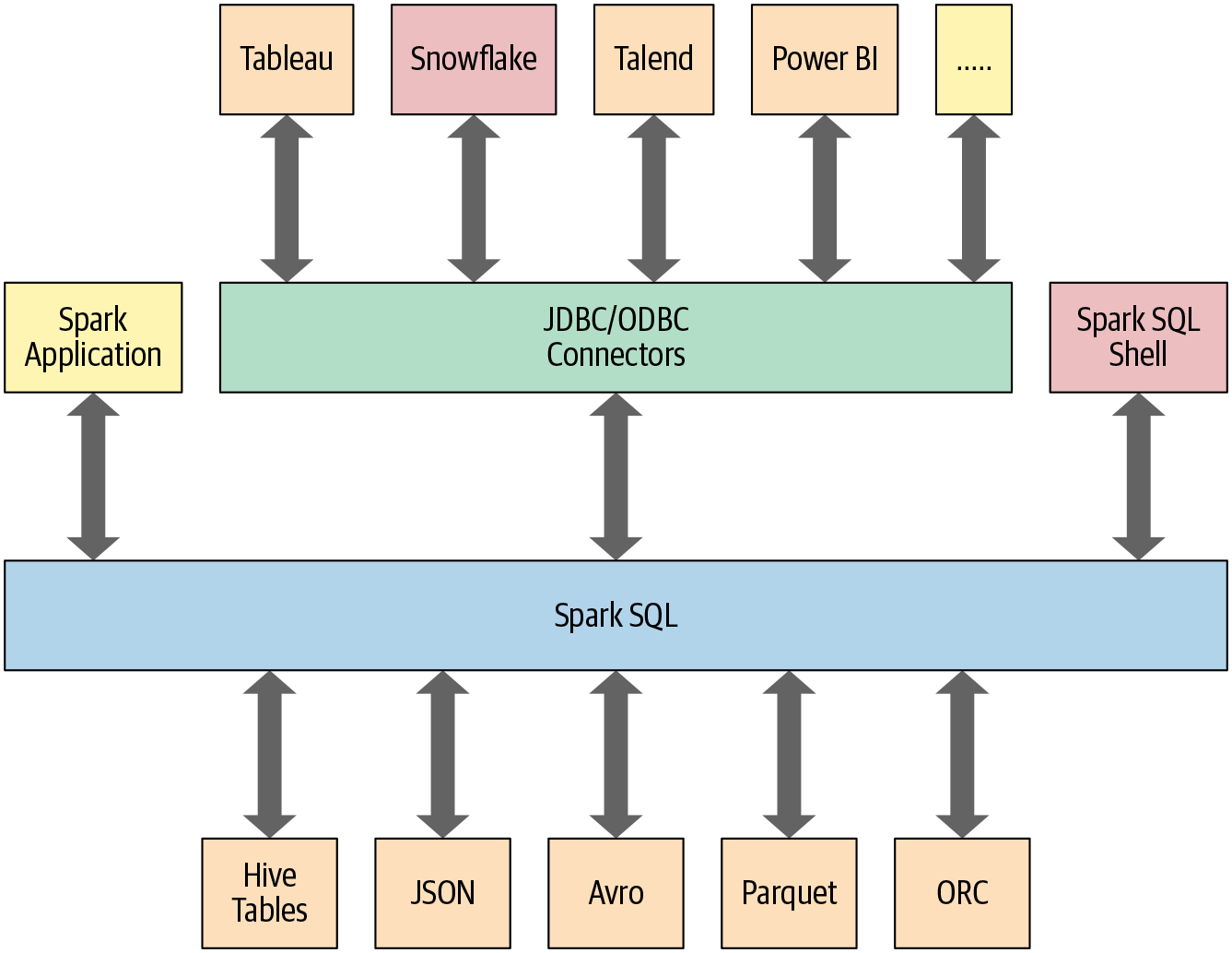
다양한 구조화된 형식(예: JSON, Hive 테이블, Parquet, Avro, ORC, CSV)으로 데이터를 읽고 쓸 수 있다.
-
Tableau, Power BI, Talend와 같은 외부 비즈니스 인텔리전스(BI)부터 MySQL 및 PostgreSQL과 같은 RDBMS등 에서 JDBC/ODBC 커넥터를 사용하여 데이터를 쿼리할 수 있다.
-
Spark 애플리케이션의 데이터베이스에 테이블 또는 view로 저장된 정형 데이터와 상호 작용할 수 있는 프로그래밍 방식 인터페이스를 제공한다.
-
정형 데이터에 대해 SQL 쿼리를 실행하기 위한 대화형 셸을 제공한다.
SparkSql 사용하기
SparkSession은 정형화 API로 스파크를 프로그래밍하기 위한 진입점을 제공한다. SparkSession을 이용하면 쉽게 클래스를 가져오고 코드에서 인스턴스 생성 가능하다.
먼저 SQL 쿼리를 실행하기 위해서 spark라고 선언된 SparkSession 인스턴스에 sql() 함수를 사용한다.
이러한 형식의 모든 spark.sql() 쿼리는 추가적인 스파크 작업이 가능하도록 데이터 프레임을 반환한다.
spark.sql 예제
날짜, 지연거리, 출발지, 목적지 등 미국 항공편에 대한 데이터세트로 기본 쿼리 예제를 살펴보자.
데이터셋 - https://github.com/databricks/LearningSparkV2/tree/master/databricks-datasets/learning-spark-v2/flights
먼저 데이터세트를 임시 뷰로 읽어 SQL 쿼리를 사용할 준비를 한다.
from pyspark.sql import SparkSession
# create SparkSession named spark
spark = (SparkSession
.builder
.appName("SparkSQLExampleApp")
.getOrCreate())
# dataset path
csv_file = "./data/departuredelays.csv"
# Read data and create temporary view
df = (spark.read.format("csv")
.option("inferSchema", "true")
.option("header", "true")
.load(csv_file))
df.createOrReplaceTempView("us_delay_filghts_tbl")
df.show()
# 스키마 지정
# schema = "'data' STRING, 'delay' INT, 'origin' STRING, 'destination' STRING"
임시뷰 출력 결과

[장보윤. 89p 중간부터 ~ 92p]